Data Analysis
Straightening Algorithm for Profilometry Data Correction
Python
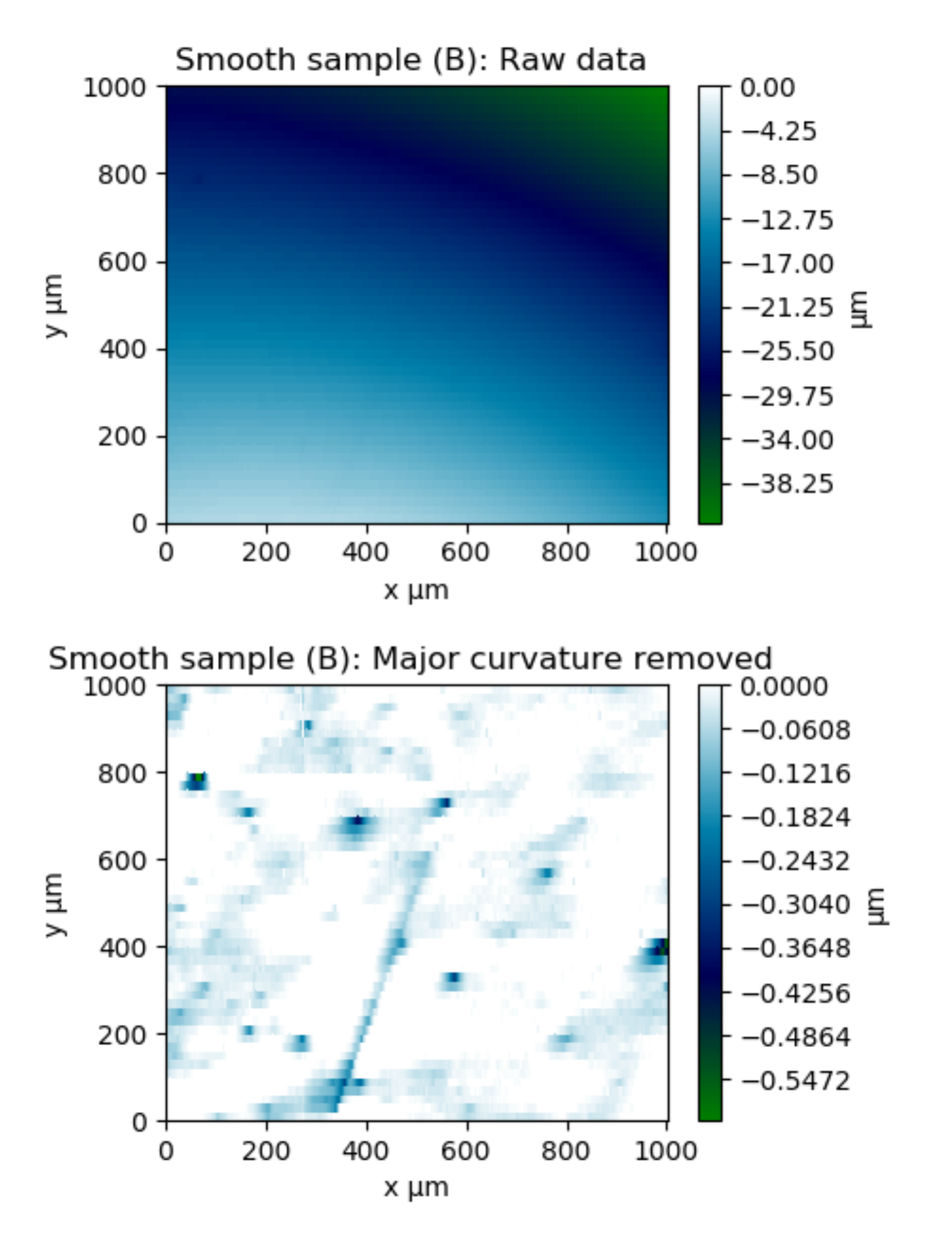
Data: Surface topography of a metal sample measured by stylus profilometry.
Objective: Study the depth of pores in the alloy’s microstructure. Profilometry resolution was sufficient, but tilt and polishing-induced curvature obscured the pores.
Method: A straightening algorithm was applied to the profilometry data. Polynomial functions of progressively increasing degree were fitted to the raw data, and the resulting fits were subtracted iteratively. This procedure corrected surface tilt and removed major curvature, allowing the true surface profile to emerge.
Outcome: The surface roughness originating from the alloy’s porous microstructure became clearly visible, providing a more accurate representation of the sample’s true topography.
Simple UI for Convolution
Python, Shell Script
Data: Computational momentum distribution data.
Objective: Convolution codes were obtained from a collaborator. They were well-written, but difficult to apply without knowledge of Python.
Method: I created a simple text-based UI in Python that uses the convolution codes as modules. This enabled one-line execution from the Linux terminal with user-specified parameters and file I/O.
Outcome: Made the advanced Python scripts written by the collaborator easily usable by all lab members.
Arrhenius Law Fit for Hydrogen Absorption
Python
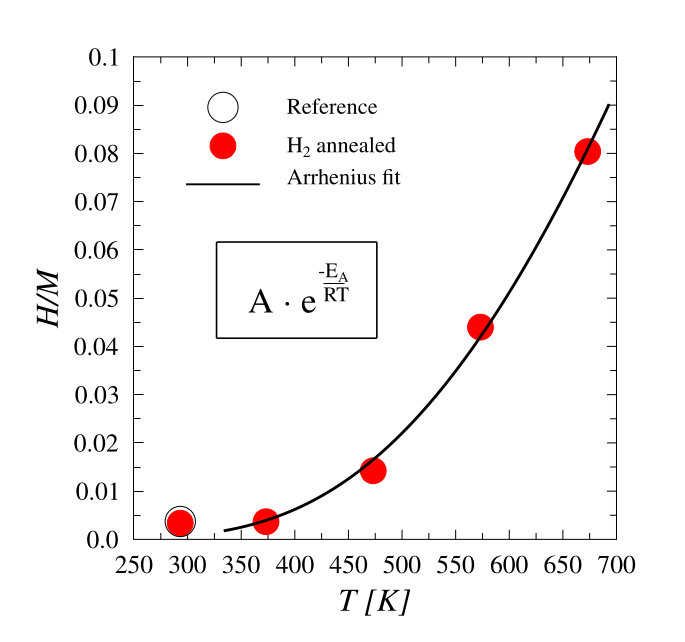
Data: Ion beam analysis of hydrogen concentration in a metal.
Objective: Determine the hydrogen absorption activation energy.
Method: The activation energy was obtained by fitting the Arrhenius model to the experimental data. Samples were saturated with hydrogen at different temperatures for the experiments.
Outcome: The Arrhenius fit yielded an activation energy of EA = 0.22 ± 0.02 eV, with goodness of fit R2 = 0.997.
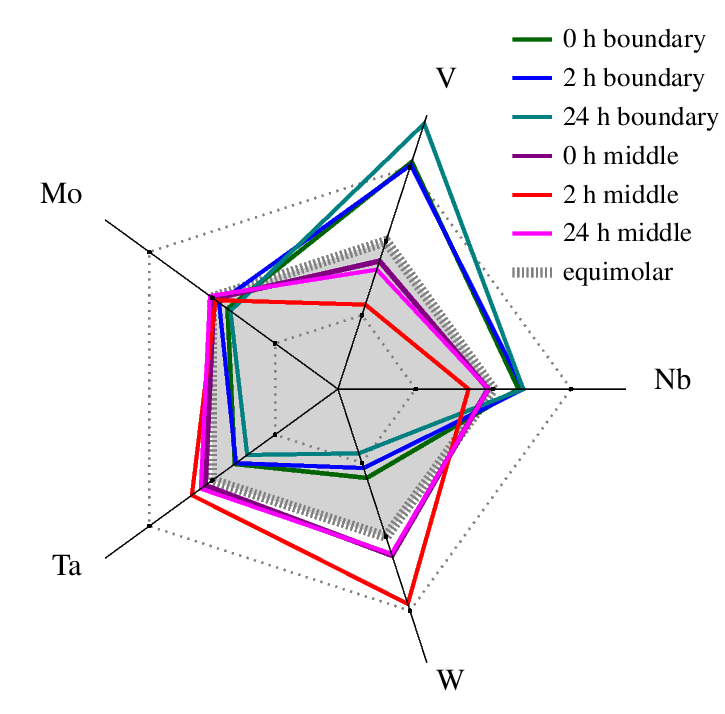
Elemental Composition Visualization
Python, Graphics Layout Engine
Data: Energy Dispersive X-ray measurements of an advanced metal alloy.
Objective: Study the elemental composition of a five-element metal alloy (V, Mo, Ta, W, Nb) and create an intuitive visualization comparing grain center, grain boundary, and the ideal alloy.
Method: Using Python for statistical analysis of Energy Dispersive X-ray data and a graphics layout engine, I created a five-axis spider plot. Colors highlighted grain centers (red–purple) and boundaries (green–blue), while the ideal equimolar composition was shown as a dashed line with shaded regions indicating deviations.
Outcome: The visualization makes it clear at a glance how elemental composition differs between measured regions and how each compares to the ideal alloy.
Statistical Analysis Fitting
Python
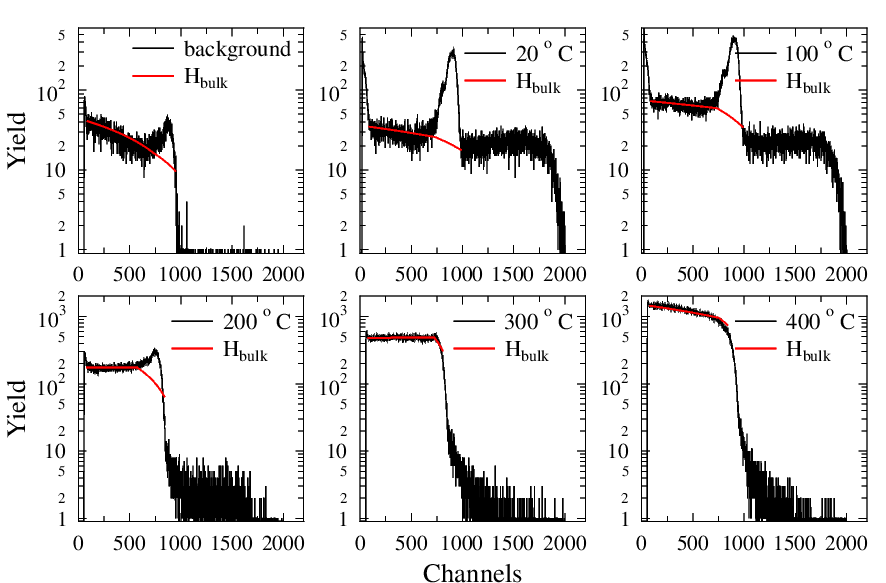
Data: Statistical data from Elastic Recoil Detection Analysis (ERDA).
Objective: Quantify the amount of hydrogen residing in the bulk of the metal sample.
Method: The raw ERDA signal includes both surface hydrogen and hydrogen absorbed into the metal. The analysis removes the surface hydrogen contribution by fitting the bulk signal shape, isolating the absorbed hydrogen signal. This allows the study of hydrogen absorption at different temperatures.
Outcome: The total absorbed hydrogen content was successfully calculated using this approach.